
La sortie de ChatGPT en novembre 2022 a marqué un gros tournant dans l’histoire, avec de grandes promesses et la révolution attendue de nos métiers. Un record absolu du nombre d’utilisateurs avec 100 millions en seulement 2 mois face à Tiktok en 9 mois ou Facebook en 4,5 ans. Le nombre de conférences en lien avec l’IA et de demandes d’acculturation a explosé en seulement quelques mois.
Avec une évolution très rapide des différents outils d’IA, les laboratoires pharmaceutiques ont souhaité se former rapidement et la course à l’intelligence artificielle a démarré. Aujourd’hui, l’objectif n’est plus de comprendre ce que l’IA peut faire mais plutôt ce qu’elle fait réellement dans nos métiers.
Même si cela peut paraître rapide, nous pouvons observer la courbe de Gartner ou Hype Cycle, qui décrit les phases que traverse toute innovation technologique avant de se stabiliser pour entrer réellement dans les usages. L’IA n’échappe pas à ces étapes. La phase de découverte est terminée pour laisser place, comme le prévoyait la courbe de Gartner, à une phase de désillusion et de maturité
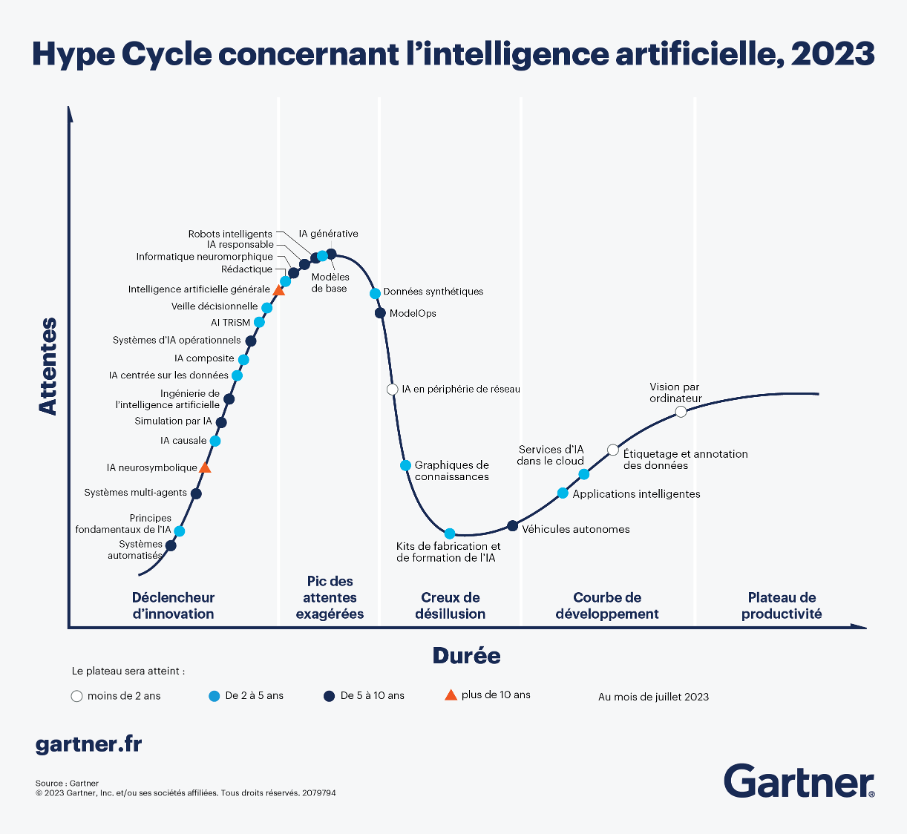
1. Le déclencheur technologique ou Innovation Trigger
OpenAI a annoncé le lancement de ChatGPT fin 2022. En donnant accès au grand public à des modèles de langage si puissants, OpenAI a permis à tous de découvrir la génération de texte, de code, de traduction… Grâce au langage naturel, l’IA est devenue simple d’utilisation et accessible même sans maitrise du prompt engineering.
Au sein de l’industrie pharmaceutique, l’année 2023 a ressemblé à une course contre la montre. Tout en restant très prudent face aux innovations, chaque laboratoire a voulu montrer qu’il « prenait le virage » de l’IA, pour des raisons d’image d’un laboratoire innovant mais également pour ne pas rater un atout technologique perçu comme révolutionnaire et obligatoire pour la décennie à venir.
Nous avons observé une multiplication des formations en interne notamment sur ChatGPT puis pour connaître le champ des possibles lié à l’IA. Également, différents chabots internes ont été créés pour proposer un outil sécurisé dans un environnement fermé aux collaborateurs leur permettant d’intégrer des documents confidentiels et de travailler directement sur leur base de données. Ces bots internes reposent presque tous sur les modèles d’OpenAI, labellisés différemment selon le laboratoire.
Différentes initiatives ont aussi vu le jour avec notamment les ‘AI ambassadors’ où certains collaborateurs devenaient les représentants de l’IA dans leur département ou métier pour accompagner les autres à développer leurs compétences en lien avec l’IA générative.
Ces nombreuses actions ont été accompagnées d’une forme de pression sur les équipes. Les conversations avec les collaborateurs ou échanges sur réseaux professionnels faisaient émaner une idée commune : « L’IA ne remplacera pas l’humain mais remplacera l’humain qui ne sait pas l’utiliser ». Beaucoup de collaborateurs, hésitants quant à l’utilisation opérationnelle de l’IA, se sont formés pour suivre la tendance globale et ne pas se sentir dépassés.
Ainsi, les laboratoires pharmaceutiques ont pris le pas de l’IA sans avoir clairement défini la trajectoire à suivre mais en étant certains que dans le cas inverse, ils perdraient un atout stratégique face aux concurrents. Cette prolifération des outils et des formations a entraîné des attentes démesurées.
2. Le pic des attentes démesurées ou Peak of inflated expectations
Après la première phase d’excitation liée à la découverte d’une nouvelle technologie, les annonces se sont succédées.
Les géants ont proposé des modèles de langage toujours plus précis et puissants, des modèles de génération d’images ou de vidéos proposant des contenus plus qualitatifs et régulièrement mis à jour (Dall-E, Sora ou Runway) ou encore des assistants intelligents capables de raisonner comme des humains.
En parallèle, l’acculturation massive des collaborateurs a continué en 2024 avec des formations pour améliorer la productivité (ateliers de prompt engineering, promptathon, création de bibliothèque de prompts, génération d’images, de vidéos, de slides…). En quelques minutes, les équipes deviennent capables de créer un avatar, générer son discours par IA, l’animer et en faire différentes courtes vidéos pour les réseaux sociaux ou pour proposer du contenu interne.
Côté R&D, le nombre de partenariats entre des laboratoires pharmaceutiques et des solutions intégrant l’IA a explosé. Dans la découverte de médicaments particulièrement, les collaborations se sont multipliées pour accélérer l’identification de nouvelles molécules actives ou la découverte de cibles immunologiques.
Cet infini champ des possibles a entraîné des expérimentations et preuves de concept sur les cas d’usage semblant les plus pertinents et une communication externe affirmant la transition vers l’IA générative. Nous avons vu apparaitre des demandes de segmentation omnicanal automatisée ou encore une volonté d’obtenir des agents de veille scientifique permettant aux équipes d’obtenir leur rapport quotidien des choses clés à savoir dans leur domaine.
3. Le passage par le through of disillusionment
Pourtant, derrière les grandes promesses et attentes de l’IA, la réalité est plus contrastée avec des limites techniques, économiques, éthiques ou de sécurité. Les modèles de langage sont des algorithmes entraînés sur d’importants volumes de données. Pour générer du texte, ils vont prédire les mots suivants les plus probables. Si les données d’entrée sont biaisées, cela va se répercuter sur les données de sortie. Si elles sont partielles ou incomplètes, le modèle invente – hallucine – pour répondre à la demande de l’utilisateur. Si les données sont obsolètes, le modèle répondra mais la sortie générée sera fausse. Le jeu de données initial est critique. Dans un domaine aussi règlementé que celui de la santé, les données sont sensibles et protégées. Les résultats générés peuvent donc être inadaptés au-delà des premiers cas d’usage tels que la traduction ou la synthèse de documents.
Pour pallier cette problématique et les enjeux de confidentialité, les laboratoires ont internalisé leur bot. Il a donc fallu entraîner les modèles internes propres nécessitant une infrastructure technique robuste, des données de qualité et un contrôle des accès.
Ensuite, le coût économique et énergétique important a entraîné de nouvelles interrogations. Chaque requête mobilise une importante puissance de calcul et consomme bien plus qu’une recherche Google. L’investissement a été massif et les possibilités sont mesurées comme le nombre limité de documents PDF pouvant être analysé. Chaque laboratoire a un nombre de tokens (1 token = 0,75 mot environ) limité et les collaborateurs font parfois face à une limite du bot interne en cas de demandes répétées de synthèse de documents. D’autres collaborateurs limitent ou n’utilisent pas leur chatbot interne pour lutter contre la consommation énergétique liée.
De plus, les hallucinations sont la conséquence du modèle probabiliste qu’est l’IA. Dans le domaine de la santé, elles posent un réel problème notamment pour la synthèse précise d’un article scientifique ou d’une loi. Des approches que nous promouvons ont permis de pallier partiellement ce phénomène telles que le RAG (Retrieval Augmented Generation) qui va entraîner un découpage d’une source beaucoup plus précis. Pour la veille scientifique, l’utilisation de modèles spécialisés sur des domaines scientifiques permet une génération plus précise. De nombreuses solutions réalisant de la veille scientifique fondée sur des bases validées (PubMed, the Lancet) pallient ce problème telles que @Juisci, @PaperDoc ou encore @Klodios.
Au-delà des hallucinations, l’IA a montré différentes failles dans les textes générés : un manque de traçabilité des sources, l’utilisation de superlatifs difficile à contrer, un formalisme similaire entre chaque texte, une génération limitée en termes de longueur ne répondant pas toujours aux exigences règlementaires.
En outre, la qualité des données d’entrée est primordiale et a contribué au sein de l’industrie pharmaceutique à une désillusion. Pour beaucoup de laboratoires, les bases de données sont peu structurées et fragmentées. Nous avons observé une multiplication de cas d’usage liés à une personnalisation de l’expérience client avec l’IA ou des séquences omnicanal générées par IA et automatisées. Pourtant, la réalité est tout autre. Les fichiers Excel sont dispersés, les données ne sont pas structurées ou standardisées et toutes les données ne sont pas intégrées aux CRM. Avant d’entraîner un modèle d’IA, il est nécessaire d’obtenir un jeu de données qualitatif. C’est encore une grande difficulté pour la Pharma aujourd’hui.
Enfin, les collaborateurs ont dans leur vie quotidienne, comme le grand public, utilisé l’IA et ont accompagné les mises à jour et améliorations hebdomadaires. L’un des plus importants paradoxes de l’IA réside dans l’écart entre les politiques internes de sécurité qui bloquent les accès aux modèles puissants et le réel usage des collaborateurs. En effet, beaucoup ont choisi de complètement bloquer l’accès aux modèles dits publics et d’autoriser uniquement l’outil interne. Les motifs sont légitimes et font suite à des scandales dans d’autres secteurs comme la fuite de données sensibles, la non-conformité avec les exigences du RGPD ou encore le quasi vide juridique liée à la génération de contenus.
Cela entraîne une forme de frustration auprès des collaborateurs qui utilisent ces outils puissants dans leur vie quotidienne mais sont limités dans leur vie professionnelle. Ils contournent alors les blocages et réalisent du « shadow AI », c’est-à-dire l’utilisation de leurs comptes personnels pour avoir accès à des modèles plus performants. D’autres mettent également des documents internes dans les grands modèles de langage pour gagner en temps et en efficacité lorsque leur outil interne n’est pas assez puissant. Depuis la sortie de ChatGPT, les équipes ont été formées au champ des possibles puis les politiques internes ont restreint les usages. L’objectif n’est pas de contourner la sécurité car beaucoup ont conscience du risque de fuite des informations confidentielles mais uniquement d’être le plus productif possible et de connaître les nouveaux outils existants avec une idéalisation comme pour la génération de slides.
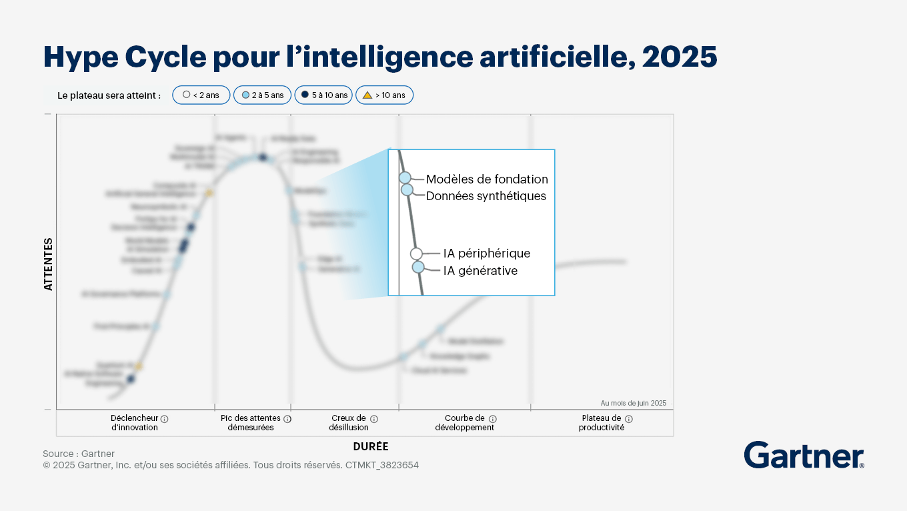
4. La fin de la hype pour entrer dans le slope of enlightenment
Après l’engouement et les attentes irréalisables, place à une phase de stabilisation. De nombreuses solutions ont été déployées au sein des laboratoires, représentant un coût très important pour l’entreprise, mais sans répondre aux besoins concrets et opérationnels des collaborateurs. Le constat est souvent le même : des investissements importants, des outils techniques de plus en plus performants et pourtant une adoption très limitée par les collaborateurs. De nombreux outils ou solutions mis à disposition n’ont pas dépassé le stade du pilote faute de cohérence avec les réels besoins ou attentes.
En 2026, nous estimons une intégration plus méthodologique de l’IA avec des cas d’usage plus précis et des bénéfices mesurables et mesurés.
Tout d’abord, l’identification des cas d’usage attendus en interne est primordiale. Un audit interne des différents processus permet de comprendre les points d’optimisation potentiels et d’implanter l’IA où elle serait réellement nécessaire. Cet audit doit être complété par des interviews de collaborateurs pour comprendre leur quotidien et les points bloquants dans leur pratique opérationnelle. Après cette première étape d’audit et d’identification des besoins, une cartographie des cas d’usage avec une priorisation et des mesures précises pour en vérifier les futurs bénéfices. Cette étape doit être réalisée conjointement par les équipes métier et support pour ne pas sous-évaluer les complexités techniques et règlementaires qui en découlent. Elle permet en outre d’identifier des quick wins qui vont motiver les collaborateurs et faciliter leur quotidien puis des projets plus conséquents qui seront réalisés progressivement sur le moyen-terme.
Ensuite, il est nécessaire de réaliser un benchmark pour recenser l’ensemble des solutions intégrant l’IA qui pourraient répondre aux besoins évoqués avec encore une fois une priorisation des solutions en fonction des pain points les plus importants, du coût d’implantation ainsi que des ressources humaines et techniques nécessaires.
La formation des collaborateurs en parallèle de l’implantation ou du pilote est cruciale pour favoriser l’adoption. Une formation continue des différents départements permet de rappeler régulièrement les biais, les limites, de favoriser l’esprit critique et de se concentrer sur une productivité englobée par de la sécurité. Des évènements comme @Pharm’AI Serie permettent aussi d’étudier des cas d’usage par département, adaptés aux réels besoins. Les ‘AI ambassadors’ réalisent ici le lien entre les formations régulières et les questions internes.
Enfin, la phase de mesure doit être mise en place avant l’implantation pour vérifier la pertinence de la solution selon les besoins du laboratoire : gain de temps, de coût, réduction des tâches chronophages ou du volume d’erreurs par exemple. Lorsque les indicateurs de performance sont prévus, un pilote peut être lancé pour évaluer la pertinence et l’adoption par les collaborateurs de la solution puis obtenir des retours d’expérience. Après 3 à 6 mois, une phase d’industrialisation commence ou au contraire le pilote s’arrête s’il n’était pas concluant.
Ainsi, la hype autour de l’IA touche à sa fin et c’est une excellente nouvelle. En trois ans, l’IA a suscité beaucoup d’engouement et d’enthousiasme puis des attentes irréalisables. Des formations express, de la frustration liée à l’impossible utilisation en interne des innovations et à des outils déployés sans valeur ajoutée pour les réels besoins des collaborateurs. Cette nouvelle période de méthode et d’intégration opérationnelle s’annonce vraiment intéressante. Les laboratoires qui réaliseront les premiers cette cartographie des besoins et benchmark des solutions correspondantes auront un réel atout stratégique face à leurs concurrents. Un point d’attention demeure cependant. Certains laboratoires qui ont connu la phase d’excitation initiale se détacheront peut-être complètement de l’IA en utilisant uniquement leur chatbot interne et perdront ce levier stratégique.
Source : Gartner Hype Cycle, 2023 et 2025
Laura Bailet , Senior Healthtech Consultant